こんにちは~ 新入社員の浮田です
まだ本格的な障害対応の経験、なんなら実務経験すらありませんが、今のうちに基礎的な自動対応の仕組みを学んでおこうと考えました。
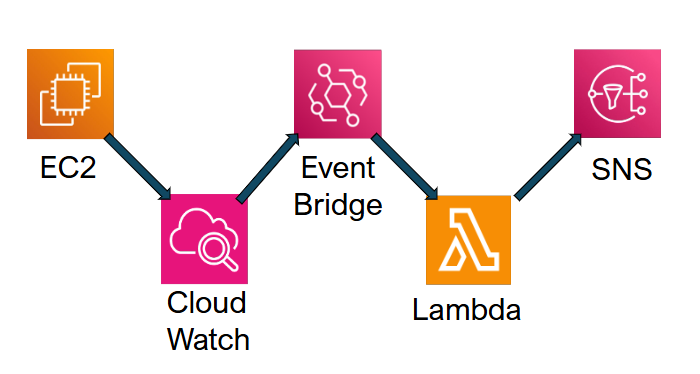
EC2のCPU使用率が高くなった場合に、自動で再起動し、通知するところまでを構築したので、その手順を備忘録としてまとめておきます。
やりたいことは
EC2のCPU使用率が高くなったら・・・
- CloudWatch でアラームを発火
- EventBridgeでLambdaを実行
- Lambdaが EC2 を再起動しつつ通知を送る
です。
手順としては
①EC2作成
②Cloud Watchアラーム作成
③SNSトピック作成
④Lambda関数作成
⑤EventBridge作成
⑥テスト:CPU使用率を意図的に上げる
①まず監視対象のEC2を立ち上げます。
特に変わったことはせずに普通に起動。
- AMI:Amazon Linux 2
- インスタンスタイプ:t2.micro
- キーペア:新規作成
- ストレージ:デフォルトでOK
こんな感じで設定しました。
②CloudWatchアラーム作成
アラームを作成を選択
メトリクスを選択→「EC2」を選択→対象インスタンスの「CPUUtilization」を選択します。

今回の閾値は1分間でCPU使用率が60%を設定しました。

アクションは後で作成するSNSトピックを選択します。
アラーム名は任意のものを作成。
これでCloudWatchアラーム作成できました。
③SNSトピック作成
SNSトピック作成を選択します。名前などを入力した後に、
サブスクリプションの作成で自分のメールアドレスやSlackに通知をさせたいときはSlackのIncoming Webhook URLなどを設定します。
今回はメールに届くようにしました。

サブスクリプションの設定した後、登録したメールアドレス宛に以下のような確認のメールが届くので添付リンクを押下します。

④Lambda作成
EC2の再起動と通知用のLambdaを作成します。
以下のように作成しました。
言語はPythonを選択しました。
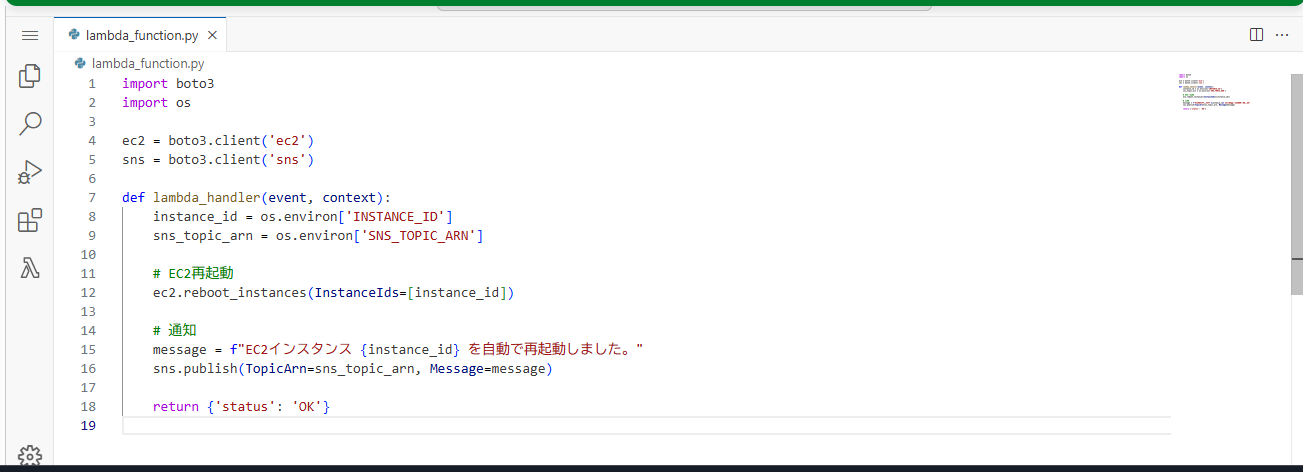
コードもコピペ用に載せておきます。環境変数は自分のものに変えてください。
import boto3
import os
ec2 = boto3.client('ec2')
sns = boto3.client('sns')
def lambda_handler(event, context):
instance_id = os.environ['INSTANCE_ID']
sns_topic_arn = os.environ['SNS_TOPIC_ARN']
# EC2再起動
ec2.reboot_instances(InstanceIds=[instance_id])
#通知(SNS経由)
message = f"EC2インスタンス {instance_id} を自動で再起動しました。"
sns.publish(TopicArn=sns_topic_arn, Message=message)
return {'status': 'OK'}
⑤Event Bridgeを作成します。
- イベントパターンを選択:
- ソース:CloudWatch
- 詳細タイプ:CloudWatch Alarm State Change
- 状態:ALARM
を選択し、ターゲットは作成したLambdaを選択します。
⑥最後に負荷をかけてテストしてみます。
まずstress コマンドをインストールします。
sudo yum install -y stress
その後、以下のようにコマンドを実行すると、CPUに一時的な負荷をかけることができます
stress --cpu 1 --timeout 100
- --cpu 1 は「1つのCPUコアを使って負荷をかける」
- --timeout 100 は「100秒間、負荷をかけ続ける」 という意味です。
EC2に入り、上記のコマンドを実施します
負荷を100秒与え続けてみました。
CloudWatchのメトリクスを見てみるときちんと負荷がかかっていることを確認できました。

メールのほうも確認してみます。
きちんと届いてました。Lambdaで設定した文言が返ってきていることが確認できました。

まとめ
この構成により、EC2の高負荷を自動で検知 → 再起動&通知までを完全自動化できます。将来的な拡張にも対応しやすい構成にしたつもりです。
実際に構築してみて感じたのは、CloudWatch アラーム・EventBridge・Lambda・SNS の連携の柔軟さと強力さです。慣れてしまえば構成はシンプルで再利用性も高く、さまざまな監視・自動復旧系の基礎になると実感しました。
今回は1台のEC2で構成しましたが、今後はAutoScalingグループに対応させたり、異常時にインスタンスを置き換える構成にも発展させていきたいと考えています。。
と思ったんですが、、
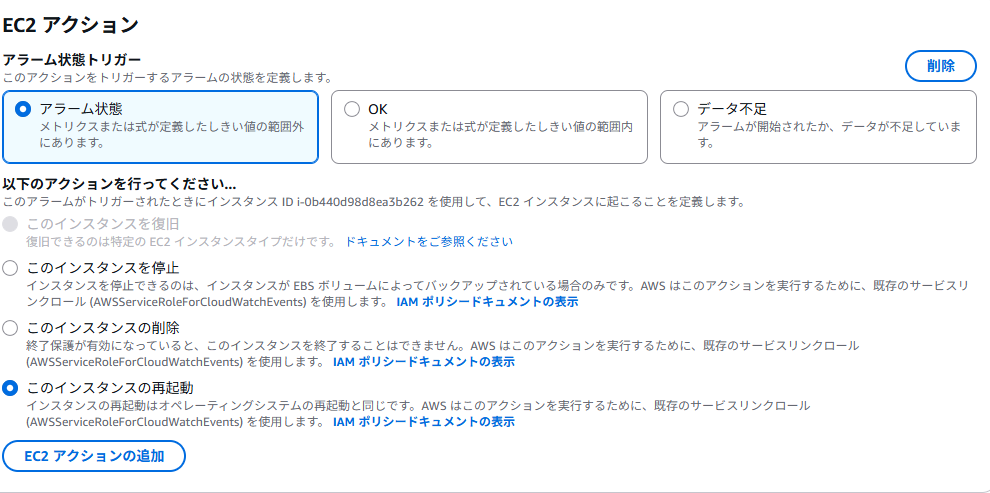
見直してみたところ、CloudWatchアラームのアクション設定の中に、
「EC2インスタンスの再起動」や「SNS通知」 を直接指定できることに気づきました。
この機能を使えば、LambdaやEventBridgeを使わずに、
CloudWatchアラームとSNSだけで再起動&通知の自動化が可能です。
最初に構成を考えた際には、拡張性を意識してLambdaやEventBridgeを組み込みましたが、
この場合はもっとシンプルな方法が存在していたことを学びました。
ベストプラクティスとは言えない構成だったかもしれませんが、
実際に構築・検証することで仕組みを理解できたので、良い学びになりました。
この再発見を踏まえて、改めて以下のようにシンプル構成での動作確認を行います:
1.EventBridgeルールを無効化し、Lambdaが呼ばれないようにします。
2.CloudWatchアラームのアクションに「EC2再起動」と「SNS通知」を直接設定します。
SNSは先ほど自分のメールアドレスを設定したものがありますのでそれを再利用します
3.再度、以下のコマンドで意図的にCPU負荷をかけます。 stress --cpu 1 --timeout 100
4.メール通知が届くかを確認します。

メール届きましたね。成功です。
ただ以下の点に注意が必要そうです。
- CloudWatchアラームが直接SNSトピックに通知する場合、
- 通知の本文は CloudWatch側で自動生成されるJSON形式の固定メッセージ です。
- 自分で文言を自由に書くことは できません。
- メールだと画像のようなフォーマットで届きます。
定型文にしたい場合は Lambdaなどを間に挟む必要あり。
最後に...
遠回りしたからこそ得られた学びも多く、結果として良いトレーニングになりました。
今後はより大規模な構成や他の自動対応パターンも試しながら、実践的なノウハウを積み上げていこうと思います。
ありがとうございました。