こんにちは~ 浮田です。
先日、Amazon Cognito にマルチリージョンレプリケーションが追加されました。
ユーザーデータや認証情報、プール設定をセカンダリリージョンへ自動同期し、リージョン障害時にも認証を止めずに済ませる、という機能です。発表を見て最初に思ったのはこれまで Cognito ってマルチリージョン構成じゃなかったんだ。です。
Cognito をマルチリージョン構成にしようとすると自前でユーザーデータを同期するしかなく、しかもフェイルオーバー時にユーザーへ強制的なパスワードリセットを強いてしまう、という構造的な問題があったそうです。
ただ、機能の使い方を追いかける前に、ひとつ引っかかったことがありました。
「そもそも自分が関わっているシステムで、BCP/DR ってどこまでやるものなんだろう?」という疑問です。このあたりを整理しきれていなかったので、この機会に調べて考えたことをまとめてみます。Cognito の解説というより、それをきっかけに考えたことのメモだと思って読んでもらえればと思います。
■ まず BCP と DR の違いから
調べてみて、自分が BCP と DR をけっこう曖昧に使っていたことに気づきました。両者は混同されがちですが、見ている対象が違います。
BCP(Business Continuity Plan / 事業継続計画) は、災害や障害が起きても事業を止めない・早く再開するための計画全体を指します。対象はシステムだけでなく、人員やオフィス、サプライチェーン、連絡手段なども含まれます。
DR(Disaster Recovery / 災害復旧) は、そのうち IT システムをどう復旧させるかにフォーカスした部分です。BCP という大きな傘の下に DR がある、という関係になります。
エンジニアが普段「DR 対応」と言っているのは、ほぼ技術的な話(マルチリージョン構成やバックアップ)に閉じています。自分もそうでした。でも本来は「そのシステムが止まると事業にどれだけ影響するのか」という事業側の視点が先にあって、その上で技術的な対策が決まるものです。順番が逆になっていたな、と反省しました。
この記事で扱うのは主に DR の領域ですが、判断の軸は常に BCP 側、つまり「事業として何を守りたいのか」に置く、という前提で進めます。
■ RTO と RPO という二つの数字
DR を考えるときに避けて通れないのが、RTO と RPO という二つの指標です。
- RTO(Recovery Time Objective / 目標復旧時間): 障害発生から復旧までに許容できる時間。「何時間以内に戻したいか」。
- RPO(Recovery Point Objective / 目標復旧時点): どこまでのデータ消失を許容できるか。「どの時点まで戻れればいいか」。
この二つを小さく(ゼロに近く)しようとするほど、必要なインフラも運用の手間も指数関数的に増えていきます。
DR の構成は、ざっくり次の四段階で語られることが多いです。
下にいくほど RTO/RPO は小さくなりますが、コストは跳ね上がります。
- バックアップ&リストア: 別リージョンにバックアップを置いておき、障害時に復元する。安いが、復旧に時間がかかる(RTO 大)。
- パイロットライト: 最小限のコア部分だけをセカンダリリージョンで常時起動しておき、障害時にスケールアップする。
- ウォームスタンバイ: 縮小版のシステムを常時稼働させておき、障害時にフルスケールへ。
- マルチサイト(アクティブ/アクティブ): 複数リージョンで常にフル稼働。RTO/RPO はほぼゼロだが、最もコストが高い。
ここで一つ思ったのは、全部のシステムを一番手厚いレベルにする必要はない、という点です。技術的にできるとつい全部盛りにしたくなるのですが、そうではなくて、システムごとに「どこまで守るか」を決めるものなんだ、と。
むしろ全部を最高レベルにするのは、設計判断としてはあまり筋が良くないとも言えます。
これまでの話を図にするとこんな感じです。(claude作)

■ 認証基盤って、特別じゃない?
ここで Cognito の話に戻ります。
DR の優先順位を考えていて、認証基盤はちょっと他のコンポーネントと違うかもしれない、と思いました。認証が落ちると、後ろの機能がどれだけ生きていても、ユーザーは誰も入れなくなるからです。
EC サイトで言えば、商品検索もカートも動いていても、ログインできなければ買い物に進めません。認証は家でいう玄関のようなもので、ここが閉まると家全体が使えなくなる。依存関係の根元にいるコンポーネントなんだな、と感じました。
認証基盤・・・すべての機能が依存する土台 = ここが崩れると後ろが立たない
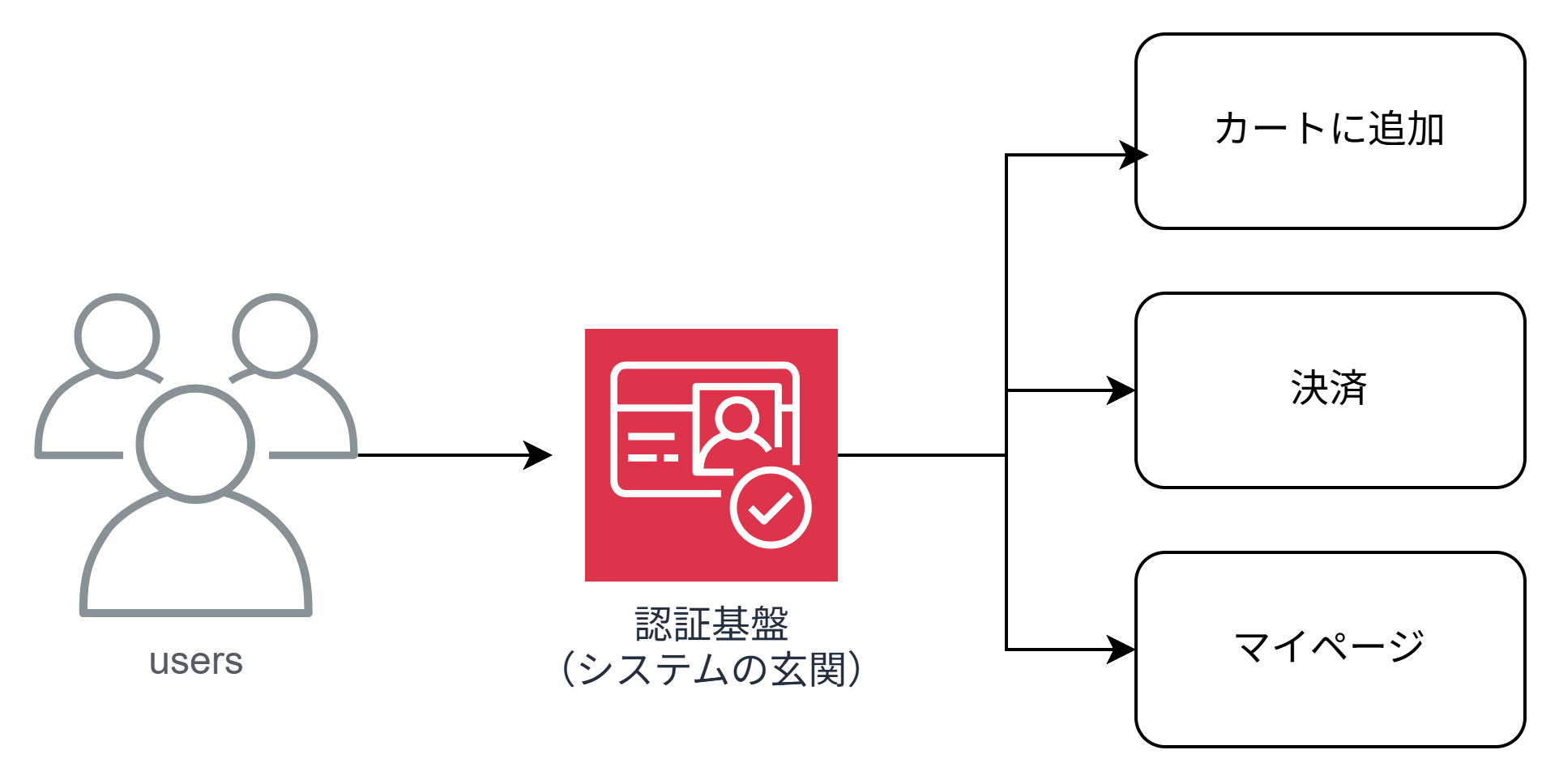
しかも認証基盤は「状態」を持っています。単にサービスが再起動すればいいわけではなく、ユーザーのアカウント情報やパスワード、セッションを別リージョンでも一貫して保てないと意味がない。だからこそ自前で同期するのは難しく、無理にやるとフェイルオーバー時にパスワードリセットや再認証を強いることになりがちでした。ログインできなくなるという体験は、ユーザーから見れば「サービスが落ちた」のとほぼ同義です。
「根元にいる」「状態を持つ」という二つの性質を考えると、認証基盤の DR は、その上に乗っているアプリケーションと同等か、それ以上に手厚くしておく価値がありそうだ、と思いました。
■ 新機能は、何を肩代わりしてくれるのか
今回のマルチリージョンレプリケーションは、まさにこの「状態を持つ認証基盤を、別リージョンへ一貫性をもって複製する」という難所を引き受けてくれる機能です。要点を整理すると、
- ユーザープロファイル・認証情報・プール設定がセカンダリリージョンへ自動同期される。複製はプライマリからセカンダリへの一方向。
- セカンダリリージョンは読み取り専用で動作する。フェイルオーバー中も既存ユーザーは既存の認証情報のままサインインでき、ログイン中のユーザーはそのまま認証が維持される(両リージョンが互いの発行したアクセストークンを認識するため)。フェデレーションサインインや SAML/OIDC、M2M 認証など各種の認証方式に対応します。
- ただし、フェイルオーバー中は新規ユーザー登録やプロファイル更新といった書き込み操作はできない。
- 前提として、保管時データを暗号化するためのマルチリージョン対応のカスタマーマネージドキー(KMS CMK)を設定しておく必要がある。
調べていて「なるほど」と思ったのが、フェイルオーバーの設定は自動ではないところです。両リージョンのエンドポイントは常時アクティブですが、いつ・どういう条件で切り替えるかは利用者側が設計します。ヘルスチェックを実装し、エラー率やレイテンシーをもとにフェイルオーバー基準を決め、DNS の切り替えなどでトラフィックを向け直す、という流れです。
そしてもう一点、見落としやすいのがOIDC エンドポイントの更新が必須だということです。マルチリージョン構成にすると新しいマルチリージョン OIDC エンドポイントへの切り替えが必要で、これはサーバーサイドアプリケーションの再デプロイや、モバイルアプリであれば App Store / Google Play への更新申請を伴います。エンドポイントを更新しないと、旧エンドポイントへのリクエストが正しくルーティングされず、ユーザーに障害として表れてしまう。地味ですが、導入計画を立てるうえではかなり重い前提だと思います。
ここから学んだのは、マネージドサービスは「全部自動でやってくれる魔法」ではない、ということでした。AWS は一番大変な「データの一貫した複製」を肩代わりしてくれますが、「いつ切り替えるか」の意思決定とその仕組み、そして周辺リソース(Lambda トリガー、WAF、ログ出力など)のセカンダリ側への用意は、依然として利用者の責任に残ります。マネージドサービスは万能の自動化ではなく、責任の分担線を引き直すものだ、という捉え方をしておきたいところです。
■ ところで、自分のシステムには本当に必要なんだろうか
ここまで認証基盤の DR は大事そう、と書いてきましたが、逆方向の問いも立てておきたいです。そのコスト、見合っていますか?
この機能はレプリカリージョンあたりで月間アクティブユーザー単位の追加料金がかかります(M2M 認証なら発行トークンへの上乗せ課金)。常時セカンダリを維持するということは、ユーザーが増えるほど平常時から払い続けるコストも積み上がっていく、ということです。
リージョン全体の障害は、起きれば重大ですが、頻度としては稀です。その稀な事態のために毎月確実に発生するコストを払い続けるかどうか——これはシステムの性質によって答えが大きく変わります。
- 24時間365日、数分の停止も許されない金融・医療・決済系: 迷わずやるべき領域。むしろやらない方が説明責任を果たせない。
- 社内向けの管理ツールや、営業時間内だけ使う業務システム: リージョン障害時は「復旧をしばらく待つ」で済むかもしれない。だとすればバックアップ&リストアで十分で、マルチリージョンはオーバースペックになる。
- その中間: 「落ちると困るが、数時間なら耐えられる」というシステム。自分が関わっているものの多くは、たぶんここに当たります。
結局は最初の RTO/RPO に立ち返って、「このシステムが N 時間止まると、事業にいくらの損失が出るか」を見積もり、それと対策コストを天秤にかける、ということなんだろうと思います。損失額より対策コストが大きいなら、その対策は過剰です。技術的にできるからやる、ではなく。当たり前のことかもしれませんが、自分はここを意識できていなかったので、いい気づきでした。
■ 自分の使うサービスでも考えたいこと
今回 Cognito を調べて、認証基盤に限らず、自分が依存しているあらゆるマネージドサービスについて同じ問いが使えそうだと思ったので、最後にメモしておきます。
- そのサービスは「状態」を持っているか。
- フェイルオーバーは自動か手動か、誰が判断するのか。
- フェイルオーバー中にできなくなることは何か。
- テストしているか。
計算するだけ・転送するだけのステートレスなサービスの DR は、別リージョンに同じものを立てればよいので比較的簡単です。難しいのはデータベースや認証基盤、ファイルストレージのように状態を持つもの。今回の Cognito の機能が価値を持つのも、まさにこの「状態の複製」が難所だからこそです。自分のシステムで状態を持っているのはどこか、棚卸ししておきたいです。
データ複製が自動でも、切り替えの判断は人間や監視システムに委ねられていることは多いです。「障害が起きたら自動で切り替わる」と思い込んでいると、いざというとき誰もボタンを押せない、という事態になりかねません。発動条件・手順・責任者を平常時に決めておく必要があります。
Cognito だとセカンダリが読み取り専用で書き込みができない、というように、たいてい「全機能がそのまま動く」わけではありません。何が動いて何が止まるのかを、ドキュメントで事前に確認しておきたいです。
これが一番大事そうで、一番抜けがちだと感じました。DR 構成は「組んで終わり」ではなく、実際にフェイルオーバーさせてみて、本当に切り替わるか、切り替わった後に業務が回るかを確認しないと、いざというときに動きません。AWS の解説でも、オフピーク時に一部トラフィックをセカンダリへ向けて検証することが推奨されています。「組んだけど一度も試したことがない DR」は、無いよりマシな程度の安心感しか与えてくれません。
■ まとめ
Cognito のマルチリージョンレプリケーションは、認証基盤の DR で難しかった部分、状態の一貫した複製と、フェイルオーバー時のユーザー体験の維持を引き受けてくれる、実務的にありがたい機能です。
ただ今回いろいろ調べてみて、機能そのもの以上に学びがあったのは、次のあたりでした。
- BCP(事業継続)と DR(システム復旧)は別物で、判断の軸はまず「事業として何を守るか」にある。
- DR のレベルは RTO/RPO から逆算するもので、全部を最高レベルにする必要はない。
- 認証基盤は「依存の根元」かつ「状態を持つ」ので、特別に手厚くする価値がある。
- マネージドサービスでも、切り替えの判断・周辺リソースの準備・検証は自分の責任に残る。
新機能が出ると「使ってみたい」が先に立ちがちですが、自分のシステムにとってそれがどのレベルで必要なのかを見極めるほうが先だな、と思い直すきっかけになりました。同じように「BCP ってどこまでやるんだっけ?」と思った人の参考になれば嬉しいです。